

Standard Data Feed Requirements for Datafeed-based indexing
The Hawksearch service enables online retailers and publishers the ability to drive a rich, compelling user experience. This experience drives visitors to the products and information that they are seeking. One main step of integration is providing a standard data feed set that the Hawksearch solution expects.
Data Feed Requirements
The Hawksearch service powers search, navigation, and merchandising aspects of a web- based application. The Hawksearch solution does not index your entire database, but it requires necessary data to drive an exceptional search experience. For example, a typical online retailer would need their product catalog indexed. Some data values that would be included in a data feed are product title, description, price, and manufacturer name.
Typically, the following files are included in a set of feeds sent to Hawksearch:
- items.txt
- attributes.txt
- content.txt
- hierarchy.txt
- timestamp.txt
Occasionally, there are additional feeds that are required. If you have the need for an additional feed than is described in this document, please discuss with your Hawksearch representative. Some of the common additional feeds are:
- 3rd party rating feed
- Custom sorting feed (for facet values)
- Custom pricing feed
Sample Data Feeds
Full Data Feed
- items.txt
unique_id name url_detail image price_retail price_sale price_sort group_id description_short description_long sku sort_default
ABC123 Leather Sandals http://onlinestore.com/products/detail.html?pid=ABC123 http://onlinestore.com/images/abc123.jpg 89.95 59.95 57.95 These leather sandals are great for the racetrack. Stylish and sleek! These leather sandals are great for the racetrack. Stylish and sleek! TEVA9825717 817
ABC12345 Leather Sandals Black http://onlinestore.com/products/detail.html?pid=ABC123 http://onlinestore.com/images/abc123.jpg 89.95 59.95 57.95 ABC123 These leather sandals are great for the racetrack. Stylish and sleek! These leather sandals are great for the racetrack. Stylish and sleek! TEVA9825717 817
XYZ789 Panini Maker http://onlinestore.com/products/detail.html?pid=xyz789 http://onlinestore.com/images/xyz789.jpg 49.95 39.95 32.95 Bring Rome to your kitchen! This Panini Maker is sure to bring tasty and unique sandwiches to any lunchtime meal. It is quick and easy to clean up as well. KRUPS1251-125 571
- attributes.txt
unique_id key value
ABC123 Color Brown
ABC123 Size 12
ABC123 hierarchy_id 1200
XYZ789 Color Black
XYZ789 hierarchy_id 1500
XYZ789 hierarchy_id 120
- content.txt
unique_id name url_detail description_short
C101 The key to happiness? Never stop learning! http://blog.onlinestore.com/2010/06/04/key-to-happiness-2/ Waaaay back when my husband David and I began dating, after years of friendship, he told me that most of the people he was working with were very, very beige. Not that they dressed in tan tones, but rather that they lived in tan tones; not a colorful character in the bunch.Of course I just had to ask if I was beige, too.
C102 What do readers say about our pizza crust? "AMAZING!" http://blog.onlinestore.com/2010/05/22/pizza-crust/ "Wow!! I've been gluten free for 4 months and I thought my other recipes were as good as it was going to get... This tastes like the REAL thing! My picky non-celiac husband said it tasted like real pizza!" - Ingrid, Maine
- hierarchy.txt
hierarchy_id hierarchy_name parent_hierarchy_id sort_order
1 Category 0
100 Shoes 1 2
110 Home 1 1
1100 Athletic 100 3
1200 Sandals 100 4
1300 Bedroom 110 10
1400 Bathroom 110 11
1500 Kitchen 110 5
120 Wedding 1 6
2 Region 0
200 United States 2 1
210 Canada 2 2
220 Mexico 2 3
2100 Midwest 200 6
2110 Padific Northwest 200 5
2120 Southwest 200 2
2130 West Coast 200 1
2140 East Coast 200 3
2150 Northeast 200 4
- timestamp.txt
2016-05-29T08:15:30-05:00
dataset full
attributes.txt 15000
items.txt 2000
hierarchy.txt 500
content.txt 50
Partial Data Feed
- items.txt
unique_id name url_detail image price_retail price_sale price_sort group_id description_short description_long sku sort_default item_operation
ABC123 Leather Sandals http://onlinestore.com/products/detail.html?pid=ABC123 http://onlinestore.com/images/abc123.jpg 89.95 59.95 57.95 These leather sandals are great for the racetrack. Stylish and sleek! These leather sandals are great for the racetrack. Stylish and sleek! TEVA9825717 817 A
ABC12345 Leather Sandals Black http://onlinestore.com/products/detail.html?pid=ABC123 http://onlinestore.com/images/abc123.jpg 89.95 59.95 57.95 ABC123 These leather sandals are great for the racetrack. Stylish and sleek! These leather sandals are great for the racetrack. Stylish and sleek! TEVA9825717 817 U
XYZ789 Panini Maker http://onlinestore.com/products/detail.html?pid=xyz789 http://onlinestore.com/images/xyz789.jpg 49.95 39.95 32.95 Bring Rome to your kitchen! This Panini Maker is sure to bring tasty and unique sandwiches to any lunchtime meal. It is quick and easy to clean up as well. KRUPS1251-125 571 D
- attributes.txt
unique_id key value
ABC123 Color Green
ABC123 Size 9
ABC123 category_id 1200
ABC12345 Color Black
ABC12345 Size 12
ABC12345 category_id 1200
- content.txt
-
unique_id name url_detail description_short content_operation C101 The key to happiness? Never stop learning! http://blog.onlinestore.com/2010/06/04/key-to-happiness-2/ Waaaay back when my husband David and I began dating, after years of friendship, he told me that most of the people he was working with were very, very beige. Not that they dressed in tan tones, but rather that they lived in tan tones; not a colorful character in the bunch.Of course I just had to ask if I was beige, too. A C102 What do readers say about our pizza crust? "AMAZING!" http://blog.onlinestore.com/2010/05/22/pizza-crust/ "Wow!! I've been gluten free for 4 months and I thought my other recipes were as good as it was going to get... This tastes like the REAL thing! My picky non-celiac husband said it tasted like real pizza!" - Ingrid, Maine D - hierarchy.txt
hierarchy_id hierarchy_name parent_hierarchy_id sort_order
1 Category 0
100 Shoes 1 2
110 Home 1 1
1100 Athletic 100 3
1200 Sandals 100 4
1300 Bedroom 110 10
1400 Bathroom 110 11
1500 Kitchen 110 5
120 Wedding 1 6
2 Region 0
200 United States 2 1
210 Canada 2 2
220 Mexico 2 3
2100 Midwest 200 6
2110 Padific Northwest 200 5
2120 Southwest 200 2
2130 West Coast 200 1
2140 East Coast 200 3
2150 Northeast 200 4
- timestamp.txt
2016-05-29T08:15:30-05:00
dataset partial
attributes.txt 6
items.txt 3
hierarchy.txt 500
content.txt 3
Hawksearch Standard Data Feed Format
Hawksearch has a Standard Data Feed Format. This format is meant to be comprehensive, flexible, and easy for all clients to create. The standard data format is designed to make it easy to add any number of attribute data for the items easily without increasing the file size too much. If you require additional columns or would like to remove a required column, please consult with the Hawksearch representative before making these changes.
Flat-File Format Properties
| Name | Description |
|---|---|
| Column Delimiter | Tab, Semicolon, Comma |
| Column Headers | Required; Must be lower-cased |
| Row Delimiter | Unix Format (in a row delimiter) |
| File Name | Lowercase and named as: items.txt, content.txt attributes.txt, hierarchy.txt, timestamp.txt |
| Data Quality | The data on the file should follow strict CSV standards. For standard CSV format please reference the link below: http://www.ietf.org/rfc/rfc4180.txt |
Double Quote Requirements
In any cases where a Field value contains a double quote, the entire field value must be enclosed in double quote AND each double quote within the value must be escaped by a preceding double quote. This indicates that the interior double quote is not the end of a data value.
- Example 1
The value for a field is: Special rate “1.79”
The value of the field would be:“Special rate ““1.79””” - Example 2
The value for a field is: Blue Rug – 36” x 48”
The value of the field would be:“Blue Rug – 36”” x 48”””
Line/Carriage Return Requirements
In any cases where a Field value contains a line return or a carriage return, the entire field value needs to be enclosed in a double quote. Without this, the import process will interpret the carriage return as the beginning of a new item.
Item Data Feed
File Name: items.txt
The Items Feed is applicable to e-commerce sites. The file consists of records that describe each product. Each record is represented by a unique ID and other values that support this unique record. The additional columns contained in this data feed file have a one-to-one relationship with the unique ID.
The unique IDs cannot be duplicated in the file. A unique ID will never have two product titles or two retail prices.
If your site contains configurable products and has a single parent product and multiple children product that associate to the parent product, you can specify these as separate line items on the item data feed. For any information that is common to both the parent and child (example: description), you can repeat that description information in both columns for the parent and child items. To specify the relationship between the parent and child item please specify the unique_id of the parent item in the group_id column value line item for the child(ren).
Please reference the items.txt sample file that was provided with the data feed guidelines for an example. In that sample item ABC123 is a parent and item with sku ABC12345 is a child item and references the id of the parent in the group_id column to specify the relationship. Group_id will be used to roll up items.
The creation of this data feed file may consist of table joins on the client’s data layer, but Hawksearch expects one file. For each row, values that don’t exist (e.g. sale price) can be left blank. If additional data values are required, they should be added to the attributes.txt file. The items.txt is the filename to use for the Item Data Feed. Also, the column headers must match the column names listed below. The column names must be lower-cased.
Pre-Configured Data Columns
| Name | Data Description | Required |
|---|---|---|
| unique_id | Unique alphanumeric ID. Must not be duplicated. | Yes |
| name | Title of item | Yes |
| url_detail | URL of Record Detail Page | Yes |
| image | URL of Thumbnail Image | Yes |
| price_retail | Floating Point Value – Retail Price | Yes |
| price_sale | Floating Point Value – Sale Price | Yes |
| price_sort | Floating Point Value – Price to be used for sorting purposes | No |
| group_id | Rollup key. If used, this field must be filled in for all items. | No |
| description_short | Searchable Short Description | No |
| description_long | Long Description | No |
| sku | Alphanumeric Manufacturer SKU / Model number. Only needed if different than unqiue_id value. | No |
| sort_default | Default sort if available on the site end for items based on an integer ran calculated on the site NOTE: For search requests this is used as a secondary sort for all items that have the same score. The score is calculated based on the keyword that the user used and the searchable data associated with the item. | No |
| Item_operation | When using partial updates this column will need to be filled out on partial files. “D” indicated that the item will need to be deleted. “A” indicated item to be added. “U” indicated an update to an item. For full files, you can leave this column empty since it will be ignored. | No |
Please note that:
- The columns not marked as required do not need to exist in items.txt
- Make sure all required column names are present
- If you wish to add columns to the file please discuss with the Hawksearch Professional Services Team

Content Data Feed
File Name: content.txt
How-to articles and non-product content can be indexed as well. Similar to the Item Data Feed, each record is represented by a unique ID and other values that support this unique record. The additional columns contained in this data feed file have a one-to-one relationship with the unique ID. Across both the items.txt file and the content.txt file the unique_id needs to be unique. Unique id should also not change, as this would affect tracking.
The creation of this data feed file may consist of table joins on the client’s data layer, but Hawksearch expects one file. For each row, values that don’t exist (e.g. image) can be left blank.
Also, the column headers must match the column names listed below. The column names are case-sensitive.
Pre-Configured Data Columns
| Name | Data Description | Required |
|---|---|---|
| unique_id | Unique alphanumeric ID. Must not be duplicated. | Yes |
| name | Title | Yes |
| url_detail | URL of Record Detail Page | Yes |
| image | URL of Thumbnail Image | No |
| description_short | Description – Since this is non-product content, include the full text of the content. Strip out all tab, carriage return, and line feed characters | No |
| content_operation | When using partial updates this column will need to be filled out on partial files. “D” indicated that the content will need to be deleted. “A” indicates content to be added. “U” indicates an update to a piece of content. For full files you can leave this column empty since it will be ignored. | Yes for Partial Updates |
Please note that:
- Attributes can be associated with content if the unique_id values match.
- Attributes can be associated using the Attributes File (as long as unique_id values aren’t duplicated), or by creating a new Content Attributes File. Please consult with your Hawksearch representative to determine the best option for your implementation.
- When adding a category hierarchy that is specific to content, it must be added to the Hierarchy feed with a new root. (That root will have a parent_hierarchy_id of 0.)
This is a screenshot example of the content.txt file:

Attributes Data Feed
File Name: attributes.txt
The Attributes Data Feed file consists of records that relate to unique IDs. There may be multiple records related to a unique ID. Each record consists of a unique ID, an attribute key name, and an attribute value.
For example, ten rows can exist in the Attributes Data Feed that relate to one unique ID. These ten rows describe that the unique ID is in five different product categories, has three different colors, is for a woman, and is a clearance item.
The creation of this data feed file may consist of table joins on the client’s data layer. Hawksearch will be expecting one file, attributes.txt, to include all related attributes to the unique ID. To add additional attributes in the future, additional records would be added to attributes.txt.
Pre-Configured Data Columns
| Name | Data Description | Required |
|---|---|---|
| unique_id | Unique alphanumeric ID. Must not be duplicated. | Yes |
| key | The name of the attribute | Yes |
| value | The value for the named attribute | Yes |
Please Note:
- Attribute Keys are mapped in the Hawksearch database by lower-casing all values and replacing spaces with an underscore and removing special characters (except underscore). This is for the storing of the field name. The display name will remain for facet display.
- Attribute Values should be standardized across each Attribute Key (e.g. Blue vs Navy or Indigo) and correctly cased as it should appear on the filters. For example, if color value is blue, then you should stick to the correct casing for all items that have the color value and the casing should be consistent to what you want to have appear on facet values example (Blue)
- Hierarchy ID values should consist of the lowest level mapping of the hierarchy (category or other). Hawksearch is able to relate the higher level taxonomy items to the item by moving up parent_hierarchy_id column, therefore there is no need to reference the parents.
- If an item has more than one value for an attribute, insert multiple rows with the same key
- If an item does not have a value for an attribute, there does not need to be a row present for that unique_id and key combination. For example, if unique_id ABC123 does not have a value for the Color attribute, do not create a row in the Attributes file for ABC123 Color with null or blank for the value column. This makes the file unnecessarily large.
- For configurable products, the data used for display and sorting will be pulled from the parent product.
This is a screenshot example of attributes.txt:
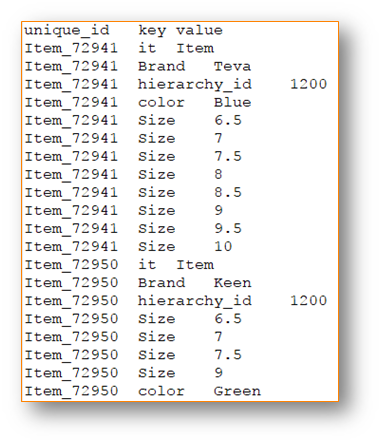
Hierarchy Data Feed
File Name: hierarchy.txt
Hawksearch supports multi-level hierarchies. For rapid deployment, we require the hierarchy.txt file to represent any hierarchical attributes that your data supports. Usually this is a category hierarchy, but other hierarchical attributes can also be defined. It is a straightforward way to represent the hierarchy in a flat file format and can support multi-level hierarchies. Unique IDs would map to these hierarchies through the Attributes Data Feed (attributes.txt). As with all data feeds, any customization to this feed will involve the Hawksearch Professional Services Team. Multi-dimensional hierarchies can be accommodated with customizations. An example of this is a category that has two parent_hierarchy_id values to map. If your data requires this, please discuss with your Hawksearch representative. It may require additional scoping for your project.
Pre-Configured Data Columns
| Name | Data Description | Required |
|---|---|---|
| hierarchy_id | Unique alphanumeric ID. Must not be duplicated. | Yes |
| hierarchy_name | The name of the attribute | Yes |
| parent_hierarchy_id | The hierarchy ID of the parent hierarchy. For the top-level properties, use 0 (zero) as the parent_hierarchy_id. Example: category or region would always have parent_hierarchy_id equal to 0. See example file below. | Yes |
| sort_order | The sort order value that should be used while displaying this in the filter if it is available | No |
This is a screenshot example of hierarchy.txt. This example shows two properties that have a hierarchy structure. These would both be used to create two nested facets. If you have only one hierarchy property to define the attribute at the top (i.e. Category) will always have parent_hierarchy_id of 0:
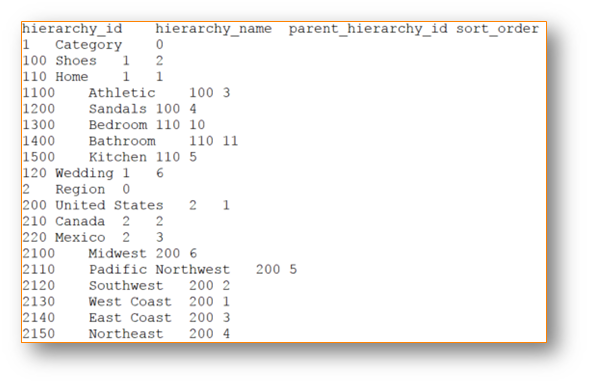
Example: What is Parent Hierarchy Id?
Timestamp / Control File
File Name: timestamp.txt
To ensure your data feeds are ready for processing, we recommend adding a timestamp/control file to the set of files that is generated by your site process. This ensures that proper checks will be in place to validate the files before they are indexed.
The timestamp file contains the following details:
- The time that your process finished generating the data feeds in UTC
- Whether the dataset is a full or partial feed
- The name of the file followed by the count of records for each of the files
Every time the Hawksearch process runs to index the new data, we use the data provided in the timestamp file to run a series of checks.
Download Timestamp File
The timestamp file is downloaded from the web accessible URL or the FTP server. This will enable the Hawksearch process to verify that the site is generating files at an agreed upon frequency.
Timestamp check
The first check consists of checking the date and time of the files provided. If the Hawksearch process is expecting the site to generate a file every 3 hours. The process checks the timestamp file and it is from 6 hours prior, the Hawksearch will not download or reprocess the files. The process will throw an error to notify the team that files are out of date.
Partial or Full Feed
The next check consists of establishing if the data files are full or partial feeds. Based on this information, we run the appropriate process.
File Name Check
A check will be done on the names of the files. The system will react different based on the scenarios outlined below:
- If one of the expected files are not provided, the system will throw an error.
- If the name of the file is different than originally provided, then the system will throw an error.
- If an additional file is provided with a name that was not previously established, the file will be ignored.
Line Count
The last check is on the counts of records for each of the file. The system will be confirming that the row counts provided in the timestamp file match the counts on the actual files. If the counts match, the system will proceed as normal. If the counts do not match, the system will throw an error. This is to eliminate indexing files that were partially downloaded or were corrupted during downloads. Do not include column headings in the count of rows.
This is a screenshot example of timestamp.txt:
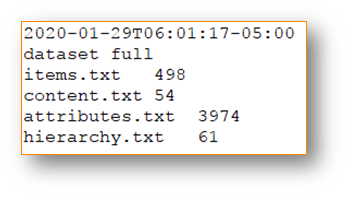
Partial Updates
Requirements
When sending feeds for a partial update, it required to include a full version of:
- Hierarchy File
- Timestamp File
- Any custom feed files
Items and / or Content Files
When sending feeds for a partial update, all required columns must be completed, unless the operation is to delete the record. The action for each item should be indicated in the item_operation column (or content_operation).
Adding – When an A is in the operation column, the record will be added to the database.
Updating – When a U is in the operation column, the existing record with the unique_id will be removed and replaced with the record being sent.
Deleting – When a D is in the operation column, the record with the unique_id will be removed from the database.
Attributes File
When adding or updating a record, ALL entries in the Attributes File belonging to the item must be included. This includes attributes that have not changed. (An update in the system, removes the existing record and replaces it with the item being sent in the partial feeds.
When deleting a record, it is not necessary to include it in the attributes file.
Hierarchy File
The entire hierarchy needs to be included with all partial or full data feeds.
Timestamp File
When building files for a partial update, the value for the dataset row in the timestamp.txt file should be ‘partial.’ Other rows should have accurate information for the number of records included in each feed for the partial update.
Rebuilding Index
HawkSearch’s search index can be rebuilt manually or through API. To build from the dashboard, login to your HawkSearch dashboard engine and click on the Rebuild Index button under the Workbench header.
The REST API can be used to automate or trigger an on-demand index rebuild process in Hawksearch. You will need an API key to use for authenticating with the API. Please contact your Hawksearch Representative to request an API Key.
The API is the preferred method for triggering the indexing process, however, if you need this to be a scheduled process on the Hawksearch end, please discuss with your Hawksearch Representative.
URL for the REST API to rebuild index: Using Dashboard API to Rebuild Indexes
Feed Delivery Method
SFTP
Files can be hosted at an SFTP location. You can host the files on your own SFTP server and provide credentials to the Hawksearch team to access the account. If you do not have your own SFTP server and need an account, ask your Hawksearch Representative to provide one.
Web Accessible URL
Files can also be hosted on a directory on your server. Please provide the Hawksearch Team the path to the files so these can be appropriately downloaded from the server. If you have the path protected, please provide the Hawksearch Team credentials for the same.
Zip File
Feeds should be delivered in a zip format. This reduces the speed at which the files can be downloaded. The file should be a standard Windows zip file with no folders within – the files should all be at the “root” when the zip file is opened.
Custom Sort Feed (Optional)
This section is to support the Custom sort option for facet values that can be selected in the Workbench.
Facet Value Sorting
When one of the built-in sorting options do not meet a client’s requirement, a Custom sort order can be defined. To implement a custom sort, a Custom Sort Feed must be used.
Some example facets that might use this:
- Size
- S, M, L, XL
- 0.5, 1⁄2, 2/3, 0.75
- 1”, 6”, 1’
- 28 Regular, 28 Long, 30 Regular, 30 Long o 14.5x32/33,14.5x34/35,15x34/35
- Days of the week
- Sun, Mon, Tue, Wed, Thu, Fri, Sat
- Seasons/Holidays
- Spring, Summer, Fall, Winter
- New Year, Mardi Gras, Easter, Mother’s Day, Graduation, Father’s Day
- Anniversaries/Birthdays
- First, Second, Third, Fourth o Tenth,Twentieth,Thirtieth
- Color/Color Families
- Red, Orange, Yellow, Green, Blue, Purple, Brown, Black o Light, Medium, Dark
- Silver, Bronze, Black, Gold, Crystal
Hawk Search Custom Sort Feed Format
This format is designed to make it easy to add sort values easily. If certain columns do not apply to your data or you need to add additional columns to existing files those changes can be incorporated. However please consult with the Hawksearch representative before making these changes.
File Format Requirements
To support a successful data import, we require the following format requirements:
| Name | Description |
|---|---|
| Encoding | UTF-8 |
| Column Delimiter | Tab |
| Column Headers | Required; Case Sensitive |
| Row Delimiter | Unix Format (\n as a row delimiter) |
| File Name | Lowercase (e.g. custom_facet_sort.txt) |
| Data Quality | The data on the file should follow strict CSV standards. For standard CSV format please reference the link below: http://www.ietf.org/rfc/rfc4180.txt |
Custom Facet Value Sort Feed
The Custom Sort Feed file consists of records that have of a facet_name, a facet_value and a sort order value. The facet_name will be the field name, as defined in the Hawksearch field section of the Workbench, that is used to build a facet that need its values sorted in a way that cannot be accomplished using the built-in Hawk functionality. There will be multiple records related to a facet_name.
For example, if a facet can have 15 possible values in the data, there will be 15 rows in the Custom Sort Feed that relate to the one field name that supplies the data to the facet. All 15 rows will have the same facet_name value, but different values in the facet_value and sort columns.
Custom Facet Sort Feed Columns
| Name | Data Description | Required |
|---|---|---|
| facet_name | Name of the field that populates the facet (as defined in the Field listing page in the Hawksearch Workbench), all in lowercase and no spaces or symbols. | Yes |
| facet_value | Facet Value | Yes |
| sort | Sort order of value (e.g. 5, 10, 15, 20 etc) | Yes |
Please note that:
- Make sure all possible field values are included for any field that is in the file. If a field value is not included, it will appear at the top of the list of displayed values in the facet.
- Make sure all sort values are unique within each field.
- It is recommended that you space your sort values by 5 or more to allow for future additions without rework.
This is a screenshot example of custom_facet_sort.txt:

Add Record to Timestamp/Control File
FILE NAME: timestamp.txt
To ensure your data feeds are ready for processing, we recommend adding a timestamp/control file to the set of files that is generated by your site process. If this is part of your feeds, a Line Count should be added for the Custom Sort Feed. The system will be confirming that the row counts provided in the timestamp file match the counts on the actual files. If the counts match, the system will proceed as normal. If the counts do not match, the system will throw an error. This is to eliminate indexing files that were partially downloaded or were corrupted during downloads.
Other Questions?
If you have any 3rd party feeds that you would like integrated into Hawksearch, please contact your Hawksearch Representative.
For questions about the data feeds that Hawksearch can accept, please contact your Hawksearch Representative.